3D Object Detection from Point Cloud on KITTI
PointNet; DBSCAN; Classification;Kitti

Lidar, or Vision, has always been a debatable question in the industry of autonomous driving. Compared with other camera sensors, Lidar is expensive, however, the calculation of distance between objects is quite accurate. Let’s see Lidar’s performance without the aid of vision.
Here, we use kitti object detection dataset as our train and test ground. 3D point cloud data is used as input, and 2D image is used purely for visualization purpose. And use PointNet , a deep learning architecture specified designed for 3D point cloud data with very good performance on classification task.
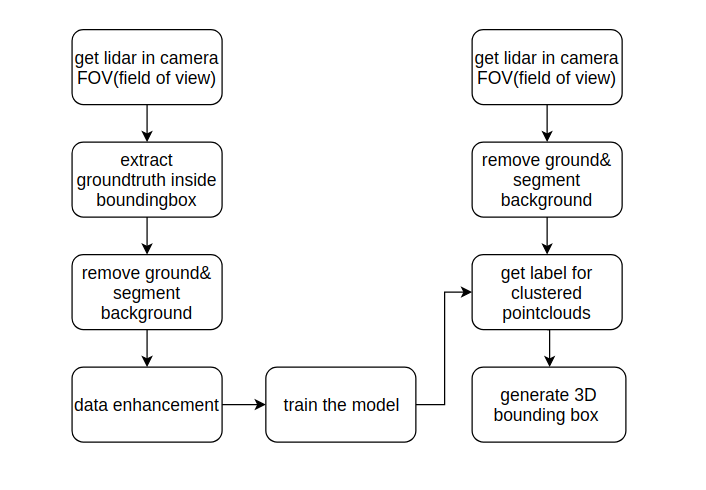
This is the flow chart of the project.
Let’s see a picture of the relationship of different coordinates in this kitti dataset. The object frame is relevant to the camera frame.
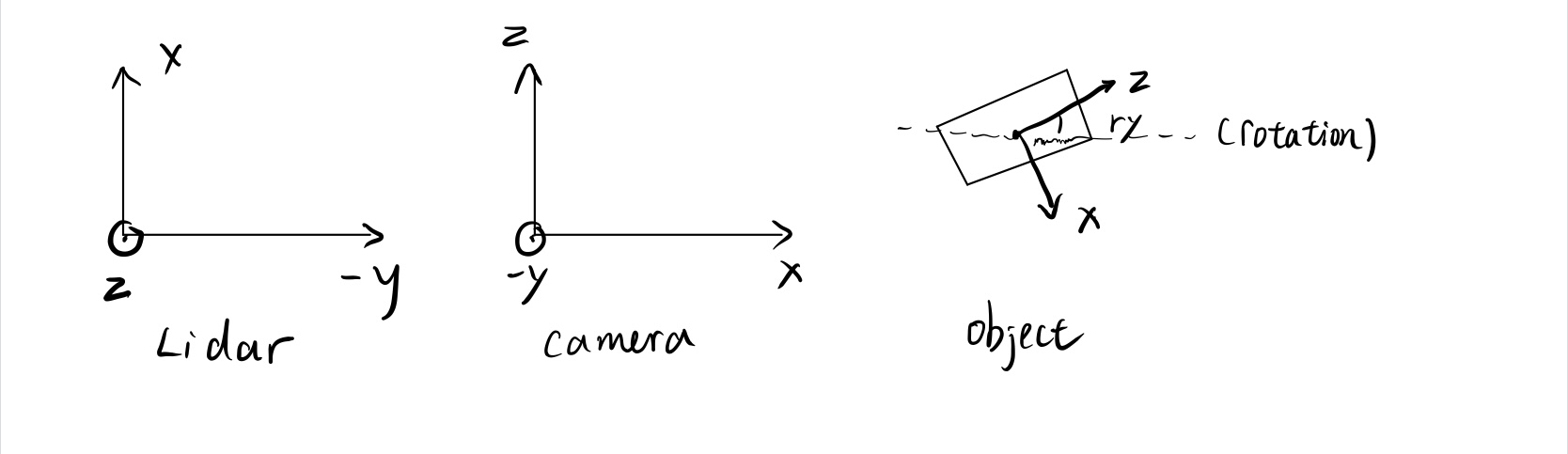
And here is the formula to transform points from lidar coordinate to image plane.
\[P_{image} = P_{rect}*R_0*T_{cam\_to\_lidar}*P_{idar}\]Since we cannot use the whole pointcloud image as the input Let’s start by preparing our training data. The goal of this step is to get separate pointcloud of different objects, for other world, to get pre-segmented data from a known scene.
1.Find the point cloud in camera field of view. Since Lidar can generate the data from 360 degree, and the camera can only see the front of the car, we don’t need to deal with point cloud outside the field of view of camera.
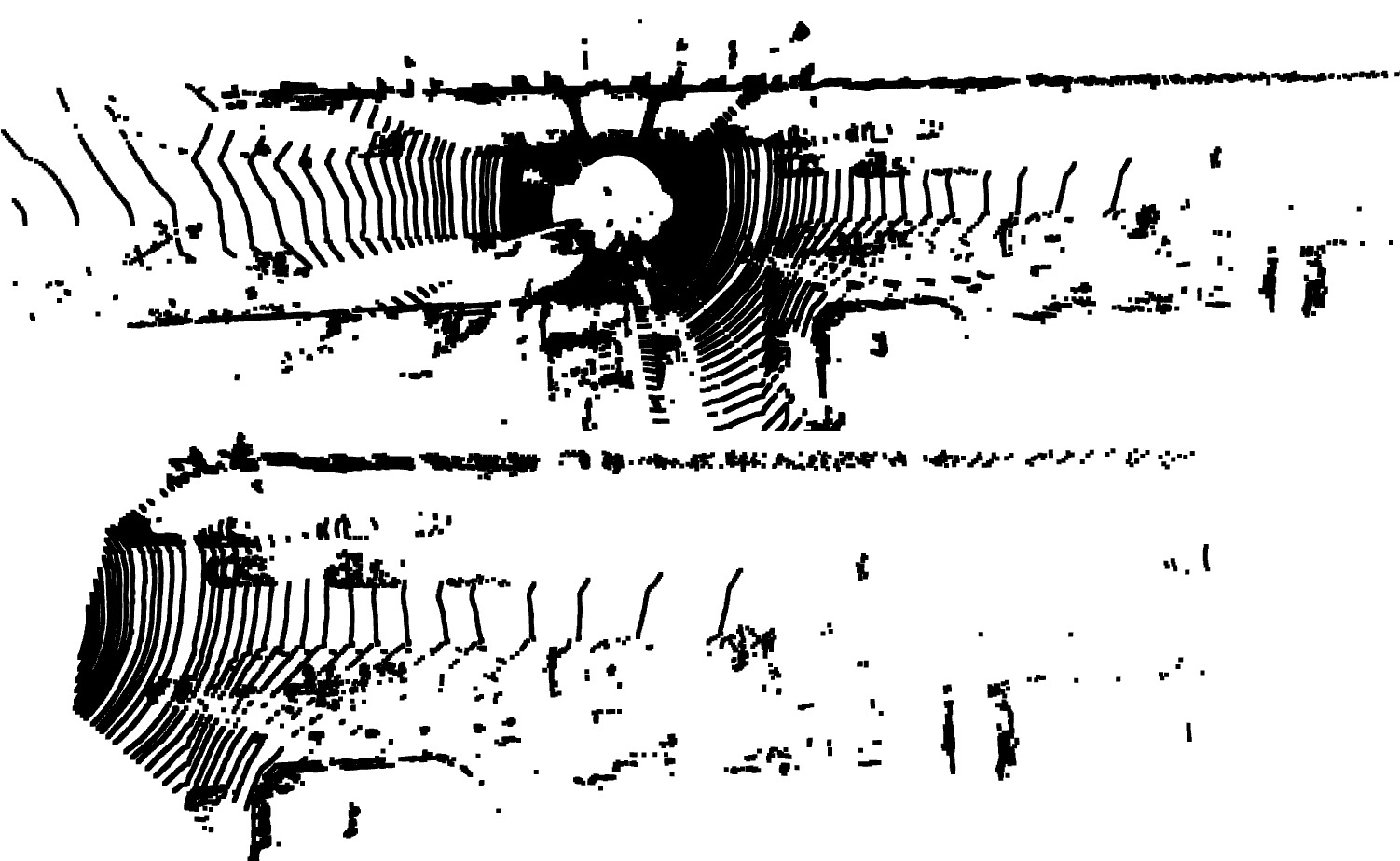
2.Extract all the groundtruth data in kitti labels. For this step, the center of the 3D bounding box in the camera frame and we need to transform them back to lidar frame to find corresponding points. After calculating the 3D groundtruth bounding box, we extract the point cloud data within the range of the box hull. We visualize the Cyclist in red, Pedestrian in green, and Vehicles in blue.

3.Next, we need to remove ground and perform clustering strategy on the remaining data, and consider individual cluster as one object, give all the objects label “Others”. The clustering method I use is DBSCAN, a density-based spatial clustering of applications with noise.
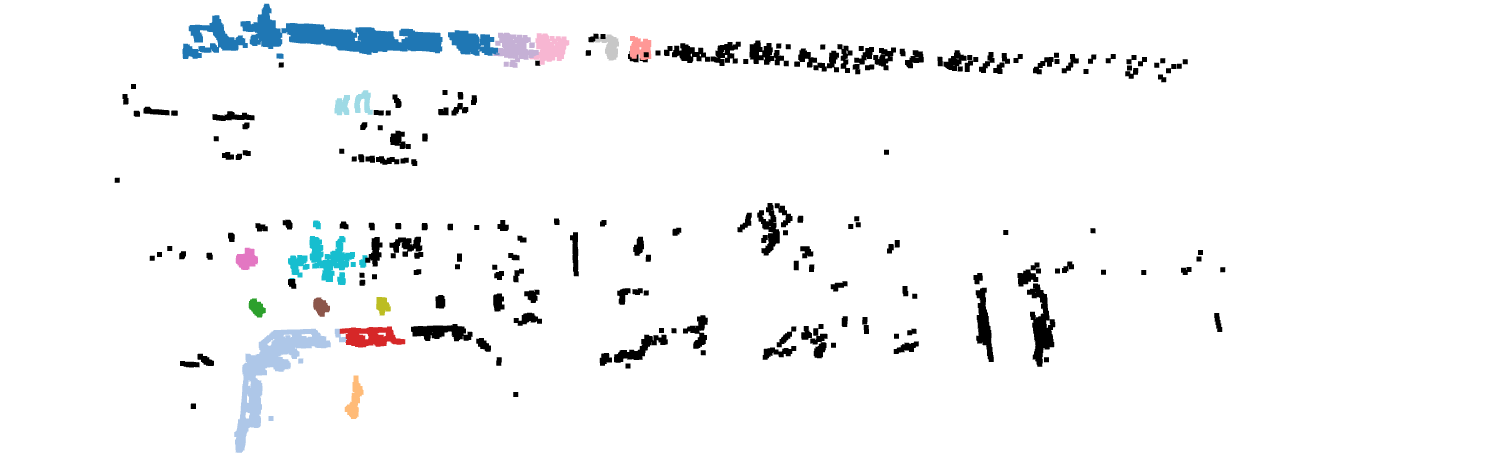
4.Final step, remove the point data with points less than 20 for Cyclist and Pedestrin, remove those Vehicle less than 100 points and save only 5000 samples for the balance of different category.
Here are four individual prepared data. Important parameters to tune in this pre-processing data setp, the distance threshold for ground removal and neighbour distance, min point for db scan.
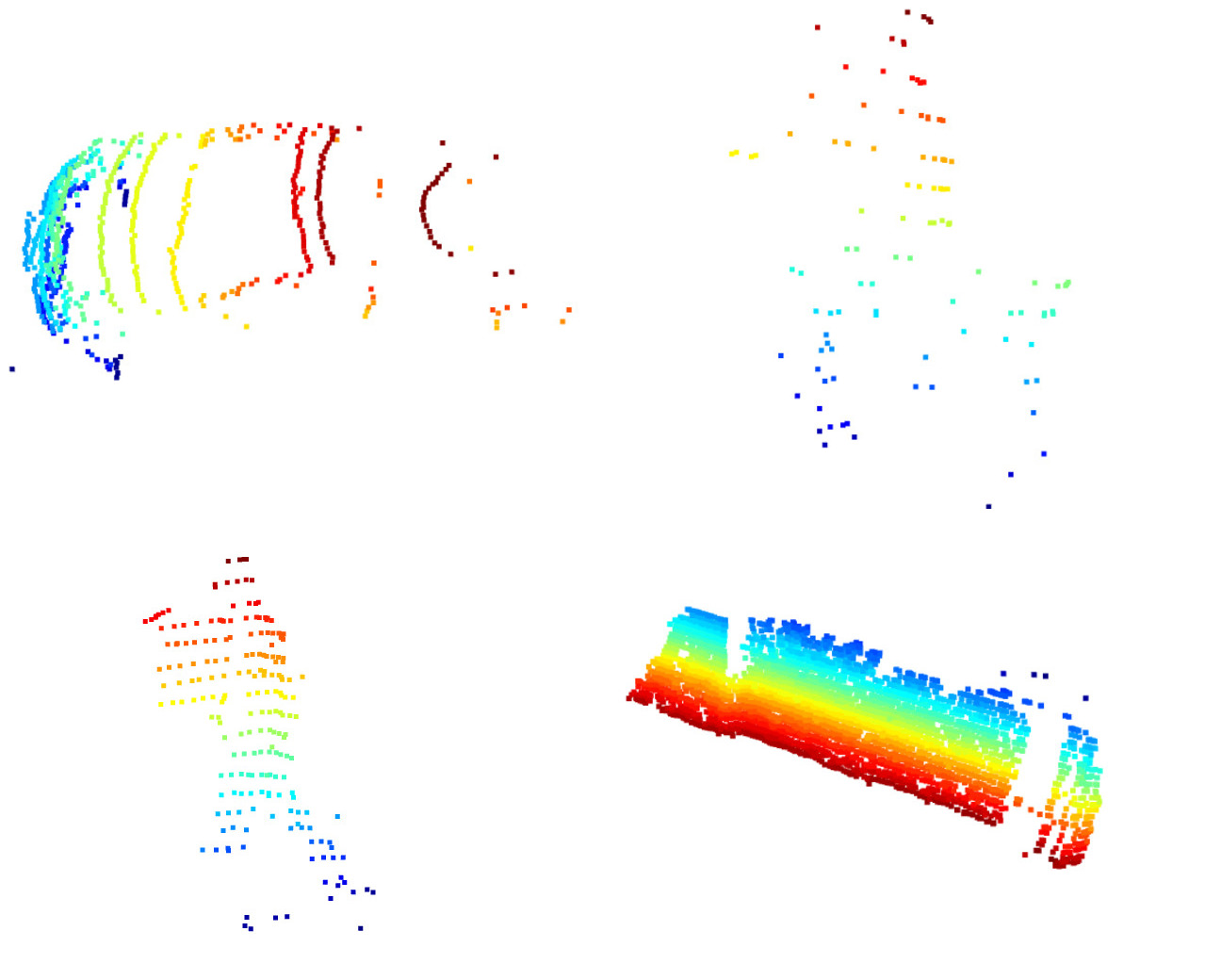
Next, we will feed all the data into training model, the model used in this project is from “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation”. Since only training data has its own groundtruth label, for better future evaluation, we use kitti_train.txt as training data and kitti_val.txt as out test data. We can reach approximately 85 percent accuracy after training of 100 epoch on test dataset.
To evaluate the result we get, we need to generate kitti-format label. So all the point cloud data needs to be transformed into a Oriented Bounding box in xy coordinate of camera. 2D bounding box is generated by 3D bounding box projection onto image plane. Here, the evaluation code provided on kitti web is modified, the overlap between 3D bounding box for all 3 categories are changed into 20%. And this is the result we get.
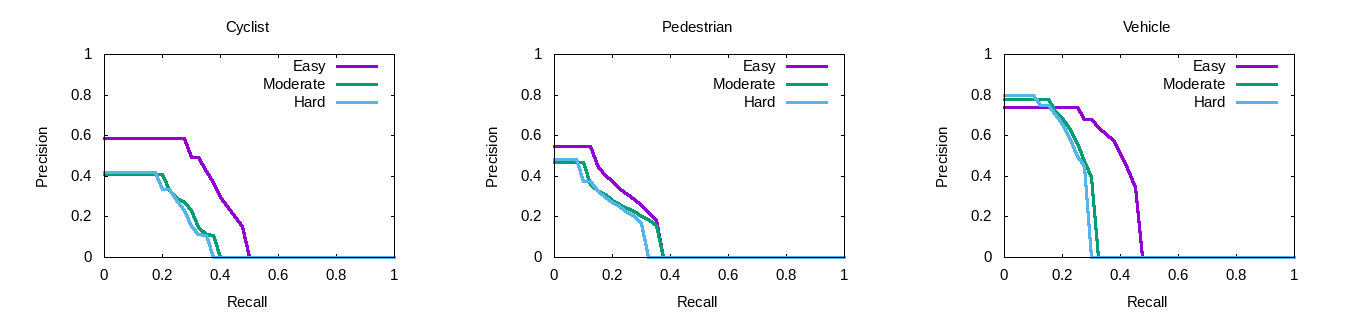
We get the highest precision on Vehicle, the precision for can reach around 0.76, and for Cyclist the precision is around 0.6 for easy data, and 0.4 for moderate and hard data. For Pedestrian, the precision is around 0.55 for easy data and 0.48 for moderate and hard data.
For more details: click here to go to github repository